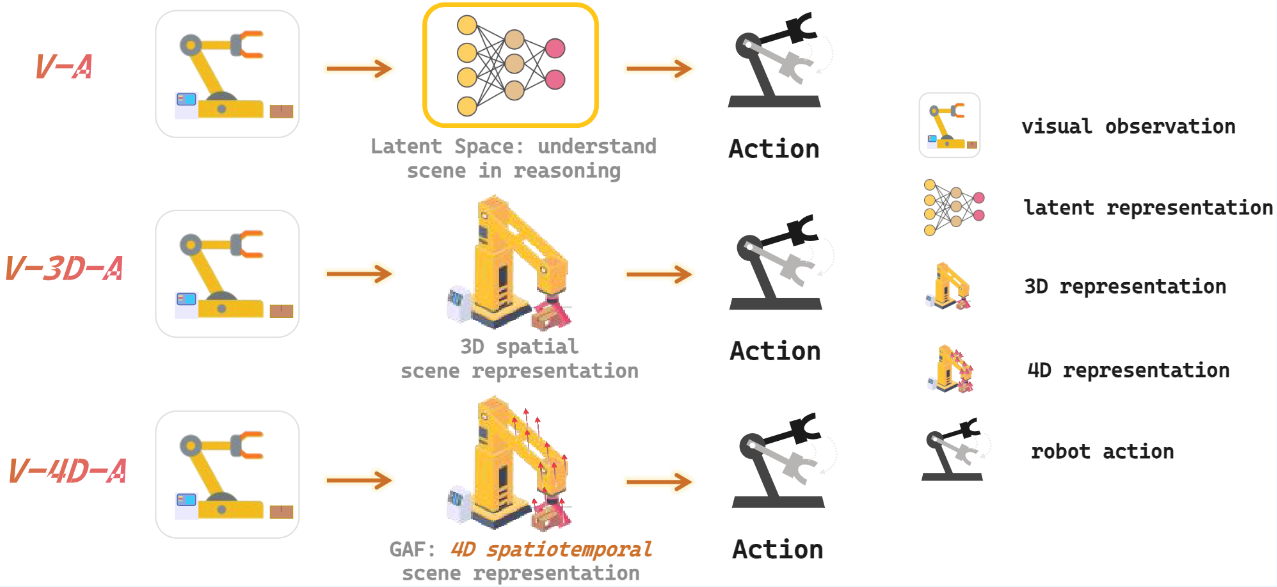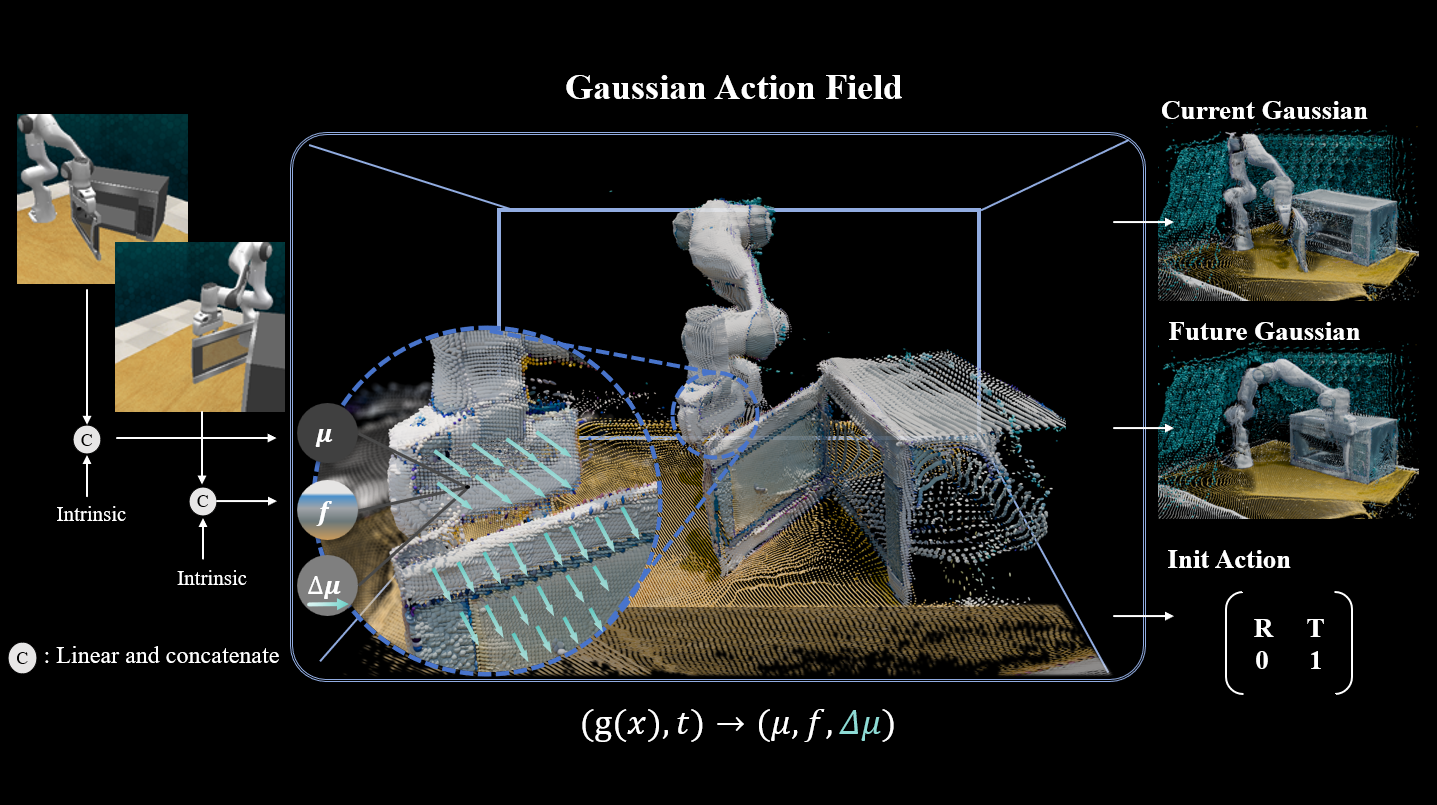
Accurate scene perception is critical for vision-based robotic manipulation. Existing approaches typically follow either a Vision-to-Action (V-A) paradigm, predicting actions directly from visual inputs, or a Vision-to-3D-to-Action (V-3D-A) paradigm, leveraging intermediate 3D representations. However, these methods often struggle with action inaccuracies due to the complexity and dynamic nature of manipulation scenes. In this paper, we adopt a V-4D-A framework that enables direct action reasoning from motion-aware 4D representations via a Gaussian Action Field (GAF). GAF extends 3D Gaussian Splatting (3DGS) by incorporating learnable motion attributes, allowing 4D modeling of dynamic scenes and manipulation actions. To learn time-varying scene geometry and action-aware robot motion, GAF provides three interrelated outputs: reconstruction of the current scene, prediction of future frames, and estimation of init action via Gaussian motion. Furthermore, we employ an action-vision-aligned denoising framework, conditioned on a unified representation that combines the init action and the Gaussian perception, both generated by the GAF, to further obtain more precise actions. Extensive experiments demonstrate significant improvements, with GAF achieving +11.5385 dB PSNR, +0.3864 SSIM and -0.5574 LPIPS improvements in reconstruction quality, while boosting the average +7.3% success rate in robotic manipulation tasks over state-of-the-art methods.
Part I: GAF Method Introduction
Part II: Simulation Experiments
Part III: Real World Deployment